2025. 5. 2. 12:33ㆍProgramming Language/C++
1. 첨자연산자란
첨자 연산자(subscript operator) operator[] 는 객체를 배열처럼 인덱스로 접근할 수 있게 해주는 연산자이다.
클래스에서 첨자연산자를 오버로딩하면 클래스에서 obj[i] 같은 구문을 사용할 수 있도록 만들 수 있게 된다.
2. 첨자연산자의 오버로딩: Vector 클래스를 사용한
이전에 사용했던 Vector 클래스를 한번 더 만들어서 사용해보도록 하자.

우리가 해보고 싶은건

이렇게 했을때 순서대로 x값, y 값 이 출력 될 수 있도록 만들어 보도록 하자.
먼저 멤버 변수를 반환할 것이기에 반환값은 int 타입이 될 것이다.
그리고 operator의 첨자연산의 경우는 []로 operator[]의 매개변수로는 index인 int 값이 들어가도록 만들어주면 된다.

그리고 만약 index가 0이 들어오면 x를 index가 1이 들어오면 y를 반환해주는데 범위를 넘어갈 수 도 있기 때문에 그냥 0보다 작거나 같으면 x를 1보다 크거나 같으면 y를 반환해주도록 분기를 만들어주자
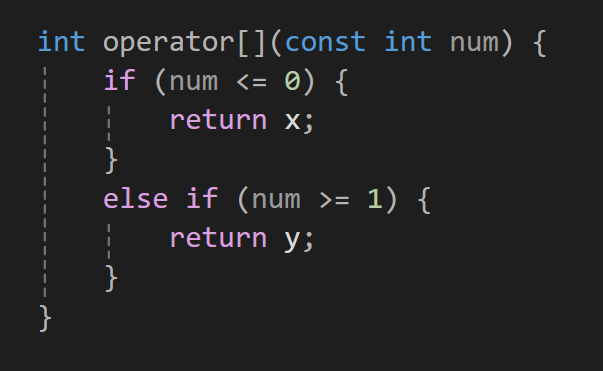
그리고 이제

이 결과를 한번 실행시켜보면

결과를 잘 출력하는 것을 볼 수 있다
그리고 추가로

이 연산도 가능하도록 하게 하고 싶은데 이게 안되는 이유는

보다 싶이 반환 값이 그냥 일반 int 값으로 값을 반환하는 것이기 때문이다.
그러면 이걸 그냥 레퍼런스 타입으로 변경해주면 되지 않을까?


실행해보면 문제 없이 값을 변경해준다.
그러면 만약에 Vector가 const라면?

이렇게 되면 첨자 연산자 오버로딩 시에도 const 함수로 선언해줘야만 한다.
왜냐면 이러면 this는 const타입이 아닌데 this로 전달되는 값은 const이기 때문이다.

그런데 이러면 또 x나 y의 값에 일반 레퍼런스로 반환이 불가능해진다.
그래서 첨자함수를 통해서 외부에서 수정을 하기 위해서는 함수를 두개를 만들어줘야한다.
그래서 const를 붙이고 반환형이 그냥 값 타입 함수인 수정이 불가능한 버전, const가 붙지 않고 반환 타입이 참조형인 수정 가능한 버전

근데 만약에 엄청 큰타입을 반환해야 하는 경우는 그냥 타입형이 아니라
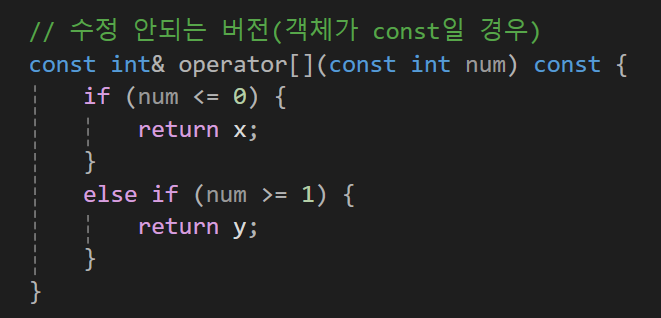
이렇게 const 참조 타입으로 반환하면 복사가 이뤄지지 않고 return 할때 가볍게 return 할 수 있게 된다.
3. 첨자연산자의 오버로딩: String 클래스를 사용한
간단하게 일단 String 클래스를 하나 만들어보자.
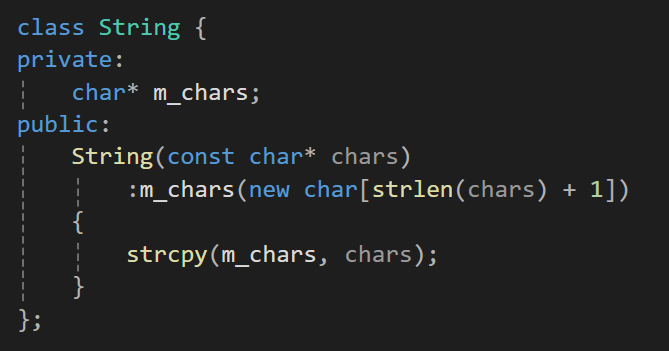
그리고 우리가 하고자 하는건 위에서 처럼
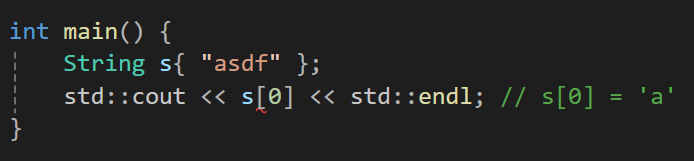
이런 출력을 바라는 것이다.
우리가 이전에 배웠던 첨자 연산을 기반으로 반환값은 char형이 될 것이고, 매개변수로는 index, int형을 받게 될것임을 알고 있기에 이를 기반으로 함수의 뼈대를 만들어보자.

그리고 이는 return하기 위한 연산자기에 const를 넣어주자(return이 아니여도 아마 필요하리라 생각된다. const인 객체의 경우는 동일하게 this를 받을 수 없기 때문인듯 싶다.)
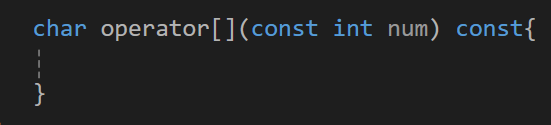
그리고 이제 내부에서 m_chars의 index를 통해서 값을 반환해주자.
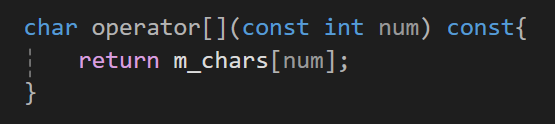
이제 출력해보면

원하는 a가 출력됨을 볼 수 있다.
그리고 이제 또 값을 변경하기 위한 함수를 하나 만들어보자면
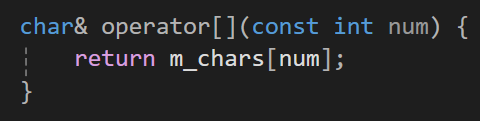
반환값을 값타입이 아니라 참조형으로 반환하고 함수를 const가 아닌 함수로 선언해주고
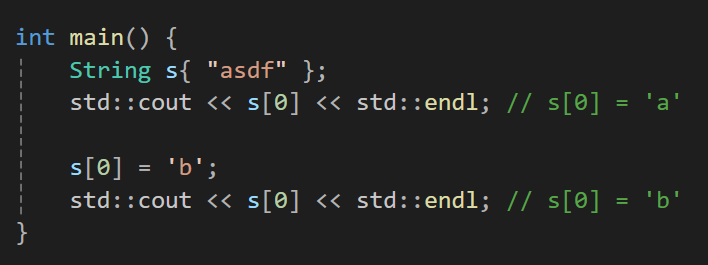
메인에서 변경 후 출력을 해보면

이렇게 값이 잘 변경되어 출력됨을 볼 수 있다.
그리고 이제 전체 String의 형태를 출력하는 형태의 연산자 오버로딩을 만들어보면

이전에 우리가 << 연산자 오버로딩 했을때 처럼 만들어주면된다
가장 앞에 friend를 넣어주고 반환 타입은 std::ostream& 타입이고 매개변수는 std::ostream& , const String& 타입으로 사용 되면 된다.

그리고 내부에서 std를 사용해서 char를 모두 출력해주면 된다.

이제 아래 코드를 실행해주면


잘 출력해주는 것을 볼 수 있다.
여기서
const char& operator[](const int num) const{
return m_chars[num];
}
=> 레퍼런스로 8바이트
char operator[](const int num) const{
return m_chars[num];
}
=> char로 1바이트
그래서 return 타입이 char인게 좀 더 효율이 좋은듯 보임... 이 정도 까지 신경 써야하는듯..
4. 첨자 연산자 오버로딩 : 해시테이블을 사용
먼저 해시 테이블에 대해서 알기 위해서 아래 접힌글을 펴서 확인해보도록 하고 시작하자.
1. 해시 테이블이란
해시 테이블(Hash Table)은 빠른 데이터 검색을 위한 자료구조 중 하나로 키(key)를 통해 값을 O(1)에 가깝게 조회할 수 있도록 설계된 구조
2. 해시테이블의 과정
해시 테이블은 단순하게 보자면 key값과 value를 쌍으로 전달하면 key값을 해시 함수라는 것을 통해서 숫자값으로 변경하고 내가 저장하는 숫자를 테이블의 크기로 나누어 나머지로 index를 생성하고 해당 테이블의 index의 위치에 key-value를 저장하는 형태로 구현된다.
이때 이 index의 위치에 key와 value를 담는 공간, index 하나하나를 가리키는 저장 공간을 버킷(bucket)이라고 부른다.
(table[0], table[1].. => 하나 하나의 공간을 버킷이라고 부름)
테이블의 크기를 index로 비교하여 index가 테이블의 어디 위치에 저장되어야할지를 지정하는 과정은
=> index = hash(key) % table_size
로 고정되어 있다.
이는 해쉬 함수를 통해 반환되는 key의 값은 무제한의 큰 정수값을 반환할 수 있기에 배열의 인덱스 범위안 (0 ~ idx-1)으로 index를 맞추기 위해서 나머지 연산이 필요하다
그러면 예를 들어
hash("apple") = 182371
hash("banana") = 987654321이렇게 나오고 해시 테이블의 크기가 10일 경우
table_size = 10
→ index = hash(key) % 10 = 1 (둘 다)이렇게 index 값이 겹칠수 있게 된다.
사실 이 해시 테이블에서는 겹칠 가능성이 매우 많기 때문에 덮어 쓸것인지 충돌이 된것인지를 검증해주는 것이 필요하다.
그래서
if (table[index].key == key) {
overwrite;
} else {
collision 처리;
}이런 처리들이 무조건 필요로 하게 되어 있다.
이를 방지하는 방법은 충돌 해결 전략이란 것으로 아래와 같은 방식들이 존재한다.
체이닝 (Chaining)
같은 인덱스에 여러 값 저장 (링크드 리스트 등으로)
table[1] → ("apple", 100) → ("banana", 200)
만약 banana라는 것을 찾으려고 한다면 먼저 table[1]을 들어가서 연결된 apple을 확인한다.
이게 banana라는 key와 맞지 않기에 연결된 노드로 들어가고 연결된 노드의 key값인 banana를 확인한다.
있다면 그 value를 반환하고 없다면 다음 노드에 key와 value를 저장한다
| 1 | hash(key) % table_size 로 index 계산 |
| 2 | table[index] 위치의 연결 리스트 탐색 시작 |
| 3 | 각 노드의 key와 비교 |
| 4 | key 일치 → value 반환 |
| 5 | key 불일치 & 마지막 노드까지 왔음 → 새 노드 삽입 |
개방 주소법 (Open Addressing)
해시 충돌이 발생했을 때, 같은 인덱스에 여러 개를 저장하는 것이 아니라 비어 있는 다른 인덱스를 찾아 저장하는 방식
table[1] 충돌 → table[2] 저장
이중 해싱 (Double Hashing)
2개의 해시 함수로 이동 폭 계산
index + i * hash2(key)
개방 주소법의 경우는 비어있는 공간을 찾기 위해 바로 옆 슬롯을 찾으러 간다.
그러면서 앞쪽 인덱스에 데이터가 몰리게 되고 그로 인해 특정 구간에 점점 더 밀집이 되면서 탐색 성능이 기하급수적으로 줄어드는, 충돌이 충돌을 부르는 현상, 클러스터링 문제가 발생한다
이를 이중 해싱은 새로운 해시함수를 추가하여 key값에 따라 다른 값을 받아서 그 값 만큼의 거리가 있는 슬롯에 가서 빈곳인지 찾게 된다.
그러면서 탐색 위치가 고르게 분산되면서 클러스터링을 방지하게 된다.
이 정도로 보고 넘어가자..
이것도 결국 구현을 보면 겁나 어려울거 뻔하긴한데..
그래서 우리가 먼저 해보고 싶은걸 확인해보면

이렇게 문자열로 index를 전달하면 그걸 통해서 value를 찾아 반환하는, 그리고 그 위치에 저장해주는 형태의 해쉬테이블을 만들어 보고자 한다.
먼저 해쉬 테이블 클래스를 하나 만들어주자.
그리고 우리는 하나 하나의 버킷을 Vector로 만들어줄 것이다.
Vector로 만드는 이유는 어쨋든 해쉬값으로 만들어진 index는 충돌이 발생할 것이고 이를 방지하기 위해서 하나의 버킷에 값이 존재할 경우 그 뒤에 값을 저장하여 충돌을 피하도록 만들어줄 것이다.(충돌해결방안중 체이닝 (Chaining) 사용)
멤버 변수로 전체 버킷을 담을 버킷으로 Vector를 선언해주고, 이 안에 각자 하나 하나 방을 가질 버킷인 Vector 타입을 추가서 선언해주자.
그리고 이 내부 버킷에는 key와 value의 쌍으로 데이터가 존재하기에 pair라는 타입으로 string, string 타입을 받아주자.
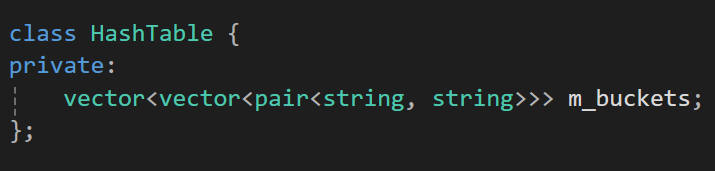
너무 복잡하니까 여기서는 std를 using을 사용해서 생략해주고 시작해주자..;;

위에서 안말했는데 이걸 사용하려면 위에 string, vector, utility(pair)를 추가해줘야만 한다.
pair에 대해서는 아래 접힌글을 확인해보자.
pair 타입
pair 타입은 C++ STL에서 아주 자주 쓰이는 기본 자료형 중 하나로 서로 다른 두개의 값을 하나로 묶는 자료형이다.
기본적인 형태는
std::pair<T1, T2>로 되어 있으며 이는 두 개의 값을 하나의 객체로 묶어서 저장할 수 있는 테이블 구조이다.
각각의 값은 first, second라는 멤버 변수로 접근이 가능하다.
#include <iostream>
#include <utility> // pair 정의
int main() {
std::pair<std::string, int> person = {"홍길동", 30};
std::cout << person.first << std::endl; // "홍길동"
std::cout << person.second << std::endl; // 30
}
pair의 유용한 함수로는 make_pair라는 함수로
std::make_pair(a, b)a, b의 값을 가지고 std::pair<decltype(a), decltype(b)> 객체를 생성해주는 함수로 직접 타입을 지정하지 않아도 되며 반환값은 반환값은 std::pair<T1, T2> 타입인 함수이다.
쉽게 말해서 make_pair(a,b)를 하면 std::pair<a의 타입, b의 타입>{a, b}를 만들어준다고 생각하면 된다.
make_pair(a,b)
=> std::pair<a의 타입, b의 타입>{a, b} 객체 반환
pair타입은 보통 서로 다른 두 타입의 데이터를 한 쌍(pair)으로 묶어야 할 때 유용하다.
이름-점수, key-value, x-y좌표, 에러코드-메세지 등등의 사용 예시가 있다.
여기서 조금 더 간단하게 만들려면 using과 클래스를 사용해서

이렇게 간단화도 가능하다.
여기서 bucket는 기능의 추가를 위해서 분리해둔 것으로 보인다.
최종적으로는
이 결과가

이런식으로 되도록 만들어 주려고 한다.
먼저 전체 버킷을 생성해주는 생성자를 하나 만들어주고

이제 첨자 연산자 오버로딩을 위한 오버로딩 함수를 만들어주자.
이때 우리가 바라는것은 key값을 넣어주면 value를 반환해주는 첨자 연산자 오버로딩을 하기 위해서기 때문에

이렇게 선언해주자.
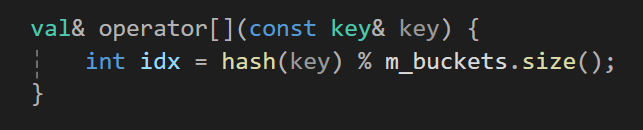
이제 key를 전달 받았을때 어떤 bucket에 넣을 것인지를 구하기 위해서 hash라는 함수에 key를 넣어주고 이 값을 버킷의 사이즈만큼 나눈 나머지를 index로 가져오자.
이제 해쉬 함수를 하나 만들어주자.
해쉬 함수는 외부에 노출되지 않아야 하기 때문에 private로 만들어주자.
해쉬 함수의 반환은 int 값이 될것이고 값은 string, key타입으로 받아줄 것이기에 매개변수는 key타입으로 잡아주자.

이제 내부에 key값을 반환해주는 알고리즘을 알아서 구현해야할것 같은데 여기서는 강사는 각각의 아스키 코드 값을 더해서 나오는 숫자를 해쉬 값으로 반환해주도록 한다고 한다.
우리도 그냥 이걸 쓰자..

그리고 다시 연산자 함수로 돌아와서 우리가 찾은 index에 해당하는 버킷을 하나 찾아서 참조로 담아주고

이제 이 버킷에 담긴 값을 가져올 방법을 찾아야 한다.
그럴려면 버킷이란 클래스에 버킷의 값을 반환하는 함수를 만들어줘야만한다.
해당 함수는 value를 참조로 반환하는(값을 넣을 수 있게 하기 위해서) 함수로 매개변수로는 key값을 받는 함수가 될것이다.
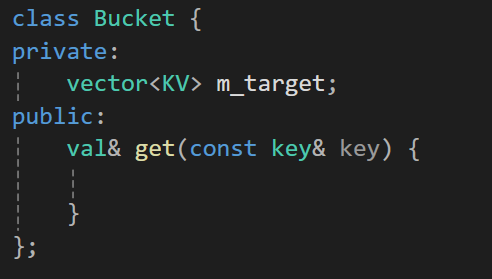
그리고 이제 이 내부에 for문을 통해서 값을 찾아주자.

그리고 만약 찾았는데도 없다 그렇다면 make_pair를 통해서 pair객체를 만들어주고 이걸 vector의 push_back 함수를 사용해서 가장 끝에 넣어주고 vector의 가장 마지막 값의 second를 반환시켜주면 된다.

그런데 여기서 value의 경우는 아직 값을 받지 않았기에 그냥 val()로 이름 없는 객체를 하나 만들어서 초기값으로 사용해주도록 해주자.(나중에 ht["key"] = "value"를 할때 ht["key"] 이 부분이 return 된 참조 second가 되면서 second에 "value"를 넣어주면서 값이 채워지는 형태로 구현된 것이다.)

그리고 이제 다시 연산자 함수로 돌아와
이 함수를 불러서 return 해주도록 하자.

이제 아래 코드를 실행시켜보면


이렇게 저장한 값을 반환하는 것을 볼 수 있다.
여기서 만약에 있는 key값에 다른 value를 전달하면 기존에 pair로 저장된 key - value의 value를 레퍼런스로 돌려주면서 대입한 값으로 변경도 가능하게 된다.


그리고 우리가 이전에 아스키코드 값을 더한것이라서 key 값을 yek로 넣어주면 동일한 해시로 충돌이 일어나게 되는데

값이 어떤 결과를 반환하는지 확인해보자.
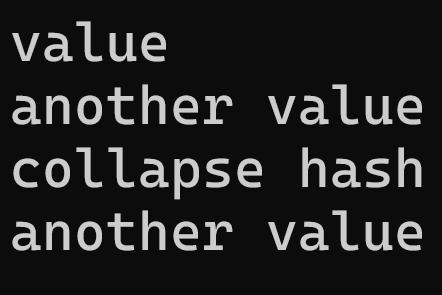
보면 정확하게 각자의 값을 가져오는 것을 볼 수 있다.
그 이유는 우리가 get에서 key 값을 index가 아니라 그냥 string으로 받아서 확인하는 과정을 가졌고

그렇기에 해당 key값으로 값이 존재하지 않는다고 판단하여 vector의 뒤에 한칸을 더 추가하여

yek값을 key로 pair를 생성하여 해당 pair의 second를 반환했고 그로 인해 값을 저장할 수 있게 됨.
여기서 우리가 이전엔 값을 못넣는 const HashTable과 같은것을 구현했는데 여기서는 이게 불가능했던건

이렇게 값이 없으면 넣어줘야 하는 부분이 있기 때문에 const로는 만들지 못했다고 함.
전체코드
#pragma warning(disable:4996)
#include <iostream>
#include <string>
#include <vector>
#include <utility>
using namespace std;
using key = string;
using val = string;
using KV = pair<key, val>;
class Bucket {
private:
vector<KV> m_target;
public:
val& get(const key& key) {
for (KV& kv : m_target) {
if (kv.first == key) {
}
}
m_target.push_back(make_pair(key, val())); // key값을 못찾으면 값을 만들어줘야함
return m_target.back().second;
}
};
class HashTable {
private:
vector<Bucket> m_buckets;
int hash(const key& key) {
int keyIndex = 0;
for (char c : key) {
keyIndex += c;
}
return keyIndex;
}
public:
HashTable(int size = 100)
: m_buckets(vector<Bucket>(size))
// vector는 무조건 동적할당이라 new 키워드 없이 동적할당함
// 그리고 소멸자에서 자동 해제되므로 더더욱 new를 쓰면 문제가 있음
// (직접 해제 해주지 않으면 메모리 누수가 되기 때문)
{
}
val& operator[](const key& key) {
int idx = hash(key) % m_buckets.size();
Bucket& bucket = m_buckets.at(idx); // 해시 충돌 발생
return bucket.get(key); // 해시 충돌 방지가 들어 있는 함수
}
};
int main() {
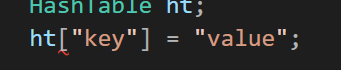
HashTable ht;
ht["key"] = "value";
std::cout << ht["key"] << std::endl;
ht["key"] = "another value";
std::cout << ht["key"] << std::endl;
ht["yek"] = "collapse hash";
std::cout << ht["yek"] << std::endl;
std::cout << ht["key"] << std::endl;
}
기본의 기본이 안되어 있으면 대 혼란 파티가 되는듯 싶다..
할때마다 C나 C++은 기초가 진짜 중요한듯 싶다...
'Programming Language > C++' 카테고리의 다른 글
| Part2::Ch 02. 연산자 오버로딩- 08. 변환 연산자 오버로딩, 변환 생성자, explicit (0) | 2025.05.03 |
|---|---|
| Part2::Ch 02. 연산자 오버로딩- 07. 대입 연산자 오버로딩, 복사 생성자 (0) | 2025.05.03 |
| Part2::Ch 02. 연산자 오버로딩- 05. 비트 연산자 오버로딩 (0) | 2025.05.02 |
| Part2::Ch 02. 연산자 오버로딩- 04. 논리 연산자 오버로딩 (0) | 2025.05.02 |
| Part2::Ch 02. 연산자 오버로딩- 03. 비교&관계 연산자 오버로딩 (0) | 2025.05.02 |