2025. 4. 29. 14:42ㆍProgramming Language/C++
1. 객체지향이란
데이터와 데이터를 처리하는 함수를 하나의 '객체'라는 단위로 묶어 다루는 프로그래밍 패러다임으로 단순하게 설명하면 변수랑 그 변수를 다루는 함수까지 한 덩어리로 묶어서 하나의 '물건'처럼 다루자라는 것으로 데이터와 기능을 같이 묶어놓고 다루는 방식을 말하는 것이다
현실 세상을 비유해보면 만약 예를 들어 자동차의 경우는 어떤 색상인지, 얼마나 속도를 내는지에 대한 데이터가 존재하고 이 자동차가 전진하고, 후진하고, 멈추는 등의 기능이 존재하는데 이전 절차 지향의 경우는 이를 각각 따로 관리했었다.
#include <iostream>
#include <string>
// 1. 데이터 구조만 따로 정의
struct CarData {
int speed;
std::string color;
};
// 2. 동작(기능)들은 따로 함수로 작성
void run(CarData& car) {
std::cout << car.color << " 자동차가 달린다! 현재 속도: " << car.speed << "km/h" << std::endl;
}
void stop(CarData& car) {
std::cout << car.color << " 자동차가 멈춘다!" << std::endl;
}
int main() {
CarData myCar{ 100, "빨간색" }; // 데이터 따로 생성
run(myCar); // 기능(함수)에 데이터(CarData)를 전달
stop(myCar);
}이렇게 데이터와 기능이 연결성이 없이 직접 사용자가 연결해 사용해야하는 경우인데 객체 지향으로 이걸 개발한다면
class Car {
public:
int speed; // 데이터
std::string color; // 데이터
void run() { // 기능
std::cout << "달린다!" << std::endl;
}
void stop() { // 기능
std::cout << "멈춘다!" << std::endl;
}
};이렇게 데이터와 기능을 묶어 사용할 수 있게 된다.
이렇게 데이터 + 기능 = 하나의 덩어리(객체) 로 사용하는 것이 객체 지향 방식이다.
2. 추가적인 단순한 객체지향의 예시
위에서는 class와 같은 아직 배우지 않은 문법을 사용해서 객체지향에 대해서 설명했는데 우리가 배운 부분으로만 한번 객체 지향에 대해서 확인해보자.

C++스타일로 작성된 내용과

C스타일로 작성된 코드를 한번 보자
C++ 스타일로 작성된 코드의 경우는 a, b가 얼만큼의 크기를 가져야하는지 몰라도 상관 없이 그냥 문자열을 넣으면 a가 받아주게 되어 있다.
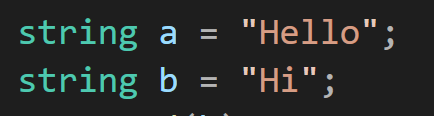
반면 C 스타일로 작성된 코드에선 문자에 어떤 문자가 추가로 붙기 위해서 문자의 크기를 어느정도 확보하고 변수를 생성해야만 하고
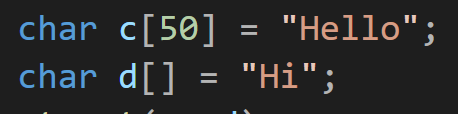
이렇게 하지 않으면 오류를 발생할 수 있는 가능성이 있다.
또한 C++ 스타일로 작성된 코드에서는 어떤 문자열에 어떤 문자열을 붙이겠다라는 부분이
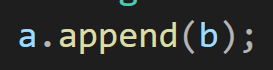
코드를 봤을때 명확하게 판단이 되고 이 함수는 어디, 누가 가지고 있는 함수라는 것을 확인 할 수 있는 반면 C 스타일의 코드의 경우는
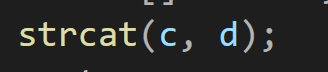
어디에 무엇이 붙을지 모르는 형태이며 어떤 것이 가지고 있는 함수, 기능이라는 것이 확인되지 않는다.
이렇게 객체 지향이 성립하기 위해서는 필요한 개념이 네가지가 존재하는데 이는 각각 캡슐화(Encapsulation), 상속(Inheritance), 다형성(Polymorphism), 추상화(Abstraction)이다.
해당 개념들을 각각 설명하기 위해서는 아마 아직 배우지 않은 개념들을 사용해야만 확인이 가능하기 때문에 이해가 어려울 수 있으나 그냥일단 이런 개념이 존재한다고 이해하고만 넘어가자.
3. 캡슐화( Encapsulation)
캡슐화는 데이터 + 함수를 하나의 단위(클래스)로 묶고 외부에는 필요한 것만 공개하는 것을 의미한다.
class Dog {
private:
int age; // 직접 접근 금지
public:
void setAge(int a) { age = a; } // 함수로만 접근 허용
int getAge() { return age; }
};
캡슐화가 왜 필요한가?
객체 내부의 상태를 아무나 접근해서 변경하지 못하게 하고 객체 스스로 관리하도록 강제함으로써 데이터의 신뢰성을 확보하고 일관성을 유지하기 위해서 캡슐화라는 개념이 발생했다.
4. 상속(Inheritance)
기존 클래스를 기반으로 새로운 클래스를 만드는 특성으로
class Animal {
public:
void eat() { std::cout << "eating..." << std::endl; }
};
class Dog : public Animal {
public:
void bark() { std::cout << "barking..." << std::endl; }
};이렇게 Dog는 Animal을 상속받아서 eat() 기능을 따로 구현할 필요 없이 그대로 사용이 가능하다.
또한 이렇게 받은 기능을 Dog에 맞게 수정도 가능하여 확장성을 얻을 수 있게 된다.
상속이 왜 필요한가?
비슷한 객체 끼리 중복 없이 기능을 공유하기 위함으로 예를 들어서 모든 동물의 경우는 먹는다라는 개념은 현실에서 통용되는 개념이며 모든 동물에게 먹는다라는 기능을 각자 만들어주는 것은 코드가 많아지며 복잡해지는 결과를 얻을 수 있게 된다.
그러하여 공통 기능은 상위 클래스에서 한번에 만들고 하위 클래스에서는 필요한 것만 추가하고 기존걸 수정해서 쓰자가 되었고 그로 인해서 코드 재사용성을 높이고, 관리가 편이해지며 유지보수성이 좋아지는 결과를 만들어 냈다.
5. 다형성(Polymorphism)
같은 이름의 함수라도 상황에 따라 다르게 동작하는 특성으로
class Animal {
public:
virtual void sound() { std::cout << "Animal sound" << std::endl; }
};
class Dog : public Animal {
public:
void sound() override { std::cout << "Bark!" << std::endl; }
};
void makeSound(Animal* a) {
a->sound(); // 실제 객체 타입에 따라 다르게 호출됨
}Animal* 타입으로 받더라도 실제로 makeSound에 전달되는 객체가 Dog라면 "Animal sound"가 아니라 "Bark!"가 출력된다.
다형성은 왜 필요한가?
여러 타입의 객체를 하나의 방식으로 다루고 싶다는 요구사항에서 발생한 것으로 하나의 카테고리가 되는 개념인 동물로써 여러 종류의 동물 타입, Dog, Cat, Rabbit 등등을 묶어 관리할 수 있게 하기 위함이다.
이로 인해서 서로 다른 클래스들이 같은 인터페이스(함수의 이름)를 통해 다르게 동작할 수 있게 하여 코드를 더 유연하고 확장성 있게 만들 수 있게 된다
6. 추상화(Abstraction)
필요한 부분만 외부에 보여주고 내부 구현은 숨기는 특정으로
class Car {
public:
void drive() { std::cout << "Driving" << std::endl; }
private:
void startEngine() { /* 복잡한 엔진 로직 */ }
};사용자는 drive만 호출하면되고 startEngine()의 복잡한 내부 로직은 몰라도 사용이 가능하다.
추상화는 왜 필요한가?
복잡한 내부 구조를 숨기고 필요한 기능만 외부에 보여줘 사람들이 이 차량이 어떻게 돌아가는지는 몰라도 시동을 걸고 엑셀을 밟으면 나아 갈 수 있는 것과 같이 시스템을 쉽게 이해하고 쓸 수 있도록 단순화 하기 위함이다
해당 내용들이 당장은 이해가 안되더라도 나중에 더 공부하다 보면 모두 이해할 수 있을 것이다.
'Programming Language > C++' 카테고리의 다른 글
| Part2::Ch 01. 클래스 - 03. 생성자(Constructor) (0) | 2025.04.29 |
|---|---|
| Part2::Ch 01. 클래스 - 02. 클래스와 객체 (0) | 2025.04.29 |
| Ch 10. 범위, 공간 - 03. 공간 기억 부류(자동, 정적, 동적) (0) | 2025.04.29 |
| Ch 10. 범위, 공간 - 02. 범위 (0) | 2025.04.29 |
| C++의 포인터 배열에 대해서 (0) | 2025.04.18 |