2024. 10. 21. 23:55ㆍProgramming Language/C
21-1 스트림과 데이터의 이동
스트림과 데이터의 이동에 대해서 이야기하기 전에 입력과 출력에 대해서 이야기를 해보자.
무엇이 입력이고 무엇이 출력인가
보통 인풋(입력), 아웃풋(출력)에 대해서 이야기를 하면 헷갈릴 수 있다.왜냐면 기존에 입력에 대한 장치, 마우스, 키보드, 카메라와 같은것 또 출력 장치, 모니터, 프린터와 같은 것은 직관적이게 입력을 하는 것과 출력을 하는게 느껴지는데 나중에는 흔히 접하는 장비가 아닌 소프트웨어 장치로도 입출력을 할 수 있게 되는데 이런 프로그래밍을 하게 되면 헷갈리게 된다.
그래서 미리 입출력의 기준을 정리해보자면 프로그램이다.
프로그램이 있고 우리가 키보드로 부터 데이터를 입력받고 입력 받는 내용들을 모니터로 출력하게 된다.
이때 외부에서 프로그램으로 데이터를 전달하는 장치가 바로 입력장치이고 프로그램에서 외부로 데이터가 나가게 하는 장치가 출력장치이다.
보통은 문자만 입력이라고 생각하는데 사실 마이크, 카메라등 어떤 형태던간 상관없이 데이터를 프로그램 내부로 보내는 장치를 입력장치라고 부를 수 있다.
그리고 위에서 말했듯이 어떤 물리적인 장치 뿐만이 아니라 소프트웨어로도 입출력을 할 수 있는데 그 대표적인 장치가 파일이다.
파일은 데이터를 읽을수도 쓸수 있는 특징을 지닌다.
- 장치라고 하지만 물리적인것 외에 소프트웨어를 사용하더라도 장치라는 말을 사용할 수 있다
- 파일은 소프트웨어로 되어있는 대표적인 입출력 장치이다
데이터의 이동 수단이 되는 스트림
위에서 말했듯이 프로그램으로 키보드를 통해서 데이터를 입력할 수도 있고 모니터를 통해서 데이터를 출력할 수 도 있다.
그럼 어떻게 키보드와 모니터로 입력과 출력이 가능할까?
기존에 printf함수과 scanf함수를 통해서 입력과 출력을 했었는데, 이 입력과 출력이 가능하도록 하게 만들어 주는 큰 역할을 하는것은 운영체제이다.
이 운영체제없이는 우리는 입력과 출력을 하는 것이 불가능하다.
그 이유는 운영체제는 어플리케이션과 하드웨어사이에서 그 둘이 원활하게 동작하도록 해주는 역할을 한다.
키보드나 모니터에서 데이터를 주고 받았다는 것은 결국 어플리케이션과 하드웨어가 서로 상호작용을 한것이고 이는 운영체제가 중간에서 연결해주는 역할을 하지 않았다면 불가능한일이다
운영체제는 그게 가능하도록 만들기 위해서 중간 다리를 놓아주는데, 출력의 경우는 출력스트림이라는 것을 만들어서, 입력의 경우는 입력스트림이란 것을 만들어 서로를 연결시켜준다.
출력 스트림...? 입력 스트림...? 생소할 수 있으나 하드웨어와 소프트웨어 사이에 운영체제가 놓아주는 연결다리라고 생각하자.
이 다리는 우리가 만들수있는게 아니라 운영체제가 제공해주는 것이다.
이 다리는 운영체제에게 우리가 다리를 놓아주는 것을 요청하여 사용한다.
그럼 우리는 요청을 한 적 없었는데 printf나 scanf를 사용할 수있었다
그 이유는 기본적으로 모니터로 데이터를 출력하는 기본적인 출력스트림과 키보드를 통해 데이터를 받는 입력스트림은 기본적으로 운영체제가 제공해 준다
그래서 우리가 프로그램을 실행하면 자동적으로 입력스트림과 출력스트림이 생성이 된다는 것이다.
그리고 프로그램이 종료되면 모두 반환이 된다.
스트림의 생성과 소멸
그럼 이걸 왜 스트림이라고 부를까
그 이유는 데이터의 이동 방향이 항상 한방향으로 형성되고 이렇게 한 방향으로 흐르는 게 물의 흐름을 연상시키기에 스트림이라고 부르는 것이다.

stdin은 표준 입력 스트림을 뜻하는 이름이다.
stdout은 표준 출력 스트림을 뜻하는 이름이다.
이 두가지가 운영체제에 의해서 자동으로 생성되는 입출력 스트림이다,
근데 우리가 보통 스트림을 만들때 누구랑 누구랑 연결되는 스트림을 만들어 주라고 요청을 하게 된다.
즉 ,목적지가 있어야 한다.
그렇기에 우리가 직접 열지않은 스트림인 표준 입출력 스트림 stdin/stdout의 경우는 그래서 기본적으로 키보드와 모니터로 연결이 형성되도록 되어 있다,
물론 이 스트림은 우리가 도착지를 설정해서 모니터 혹은 키보드가 아닌 장치를 목적지로 해서 스트림를 열수도 있다.
추후에 우리가 이 도착지를 파일로 설정해서 입력과 출력을 해볼 것이니 정확한건 가서 배우자.
그리고 위에 특이한건 stderr이다.
위에서 자동으로 생성되는 입출력 스트림은 stdin과 stdout이라고 헸는데 사실은 stderr까지 세개를 기본적으로 생성해준다.
보통은 이를 생략하고 말하는 경우도 많다.
여기서 위에서 입력과 출력을 파일로 할 수 있다고 했는데 일반적인 출력은 나는 화면으로 볼건데 버그나 에러같은 정보는 내가 파일로 만들어서 확인하겠다 라고 하게 되면 이 stderr를 통해 생성한 출력을 파일로 출력스트림을 열어서 로그정보를 확인 할 수 있도록 할 수 있다.
- stdin/stdout/stderr 와 같이 프로그램의 시작과 동시에 자동으로 형성되는 표준 스트림이 존재한다.
- 표준 스트림은 프로그램의 시작시 형성되고 종료할때 소멸된다.
- 출력 리다이렉션이란 것을 사용해서 stdout과 stderr는 데이터를 전송할 종착지를 변경할 수 있다.
21-2 문자 단위 입출력 함수
문자 입출력 함수
*하나의 문자를 출력하는 두 함수
#include <stdio.h>
int putchar(int c); => putchar 함수는 인자로 전달된 문자를 모니터에 출력한다
int fputc(int c, FILE * stream); => fputc함수의 두번째 인자를 통해서 출력의 대상을 지정한다.
===> 함수 호출 성공시 쓰여진 문자정보를, 실패시 EOF를 반환한다.
두 함수의 차이는 출력할 대상을 선택할 수 있는가 없는가의 차이이다.
putchar의 경우는 출력의 대상이 모니터로 고정되어 있다.
반면 fputc의 경우는 모니터로도 출력을 할 수 도, FILE로도 출력을 할 수도 있다.
그러면 fputc함수를 모니터로 출력을 하고자 할때는 두번째 인자로 stdin을 인자로 전달하면 된다.
*하나의 문자를 입력받는 두 함수
#include <stdio.h>
int getchar(void); => 키보드로 입력받은 문자의 정보를 반환한다.
int fgetc(File * stream) => 문자를 입력 받을 대상정보를 인자로 전달한다.
====> 파일의 끝에 도달하거나 함수호출 실패시 EOF반환위와 동일하게 getChar의 경우는 값을 키보드로 입력을 받고 fgetc의 경우는 입력받을 장치를 무엇을 사용할지 결정할 수 있다.
동일하게 입력 받을 장치를 키보드로 하고 싶다면 stdin을 전달하면 키보드로 입력을 받을 수 있게 된다.
이 위 네가지 함수는 실패 했을때 EOF라는 것을 반환을 한다.
이 EOF가 뭔지는 모르지만 그 값이 상수임을 알 수 있다.
(보통은 -1, 실패시 반환되는 값임)
fgetc를 보면 파일의 끝에 도달하거나 함수 호출 실패시 EOF를 반환한다고 했는데 결국 모두 반환하고 남은게 EOF이다.
사실 이때 반환되는게 어울리는 이유는 EOF, End Of File의 약자로 파일의 끝을 알리는 상수라는 이름을 갖고 있고 실제로 그 역할을 하기 때문이다.
문자 입출력 관련 예제

그런데 보면 ch1과 ch2의 경우 두개의 함수를 사용해서 입력을 받는데,

결과를 보면 입력에 대한 p는 하나만 존재하고 그 다음은 출력 또한 두개가 선언되어 있는데 하나만 출력되고 있다.
그 이유는 p를 입력하고 엔터를 치게 되면서 p\r\n과 같이 엔터에 대한 기호가 들어갔다
그래서 getchar함수일때 p가 들어가고 두번째 fget는 개행문자를 받아 처리해주고 있다.
그리고 아래의 p의 경우는 동일하게 putchar을 통해 출력을 모니터로 전달하고 \r\n(공백문자)는 fputc가 받고 두번째 인자로 stdout을 받으면서 출력 장치인 모니터로 내보내 처리해준다.
문자 입출력에서의 EOF
EOF는 End Of File의 약자로 파일의 끝을 표현하기 위해서 정의해둔 이름이 가진 상수로 -1이란 값을 가지고 있다.
아직은 파일 입출력을 공부하진 않았는데 어쨋든 계속 read를 하다가 데이터 없을때 EOF를 반환한다는 것에 대해선 이해가 쉬울 수 있다.
그런데 키보드의 경우는 어떻게 EOF를 보내는가?
위에 있는 fgetc함수를 통해서 키보드의 문자를 입력받았는데 키보드에서는 File의 끝이란게 존재하지 않기 때문에 EOF라는게 개념으로선 존재하지 않는다.
그렇기에 사실 입력을 끊임 없이 받을 수 있으나 어찌되었건 입력을 종료하게 될것이고 이를 프로그램에게 알려야 하기 때문에 다른 방법을 사용해야 하는데, windows에서 키보드를 통해서 ctrl + z키를 입력 받은 경우, 또는 Linux에서 키보드를 통해서 ctrl + d키를 입력하는 경우 EOF가 반환이 된다.
그래서
fgetc(stdin)과 같이 표준 입력을 fgetc에게 전달하면 키보드로 입력을 하게 되는데 windows를 쓰고 있는 경우는 ctrl + z 를 하고 엔터를 치거나, Linux의 경우는 ctrl + d 하고 엔터를 치면 입력을 종료하게 된다.
이건 이해의 영역이 아니라 그냥 이렇게 하기로 약속 해뒀기에 그냥 받아들여야할 내용이기에 그냥 그렇다고 알고 있고 이를 필요시에 방법에 맞게 사용하기만 하면 된다.

이는 내가 입력한걸 그대로 되돌려주는 프로그램으로 , 에코프로그램이라고 부르는 프로그램이다.
그래서 내가 입력한 값을 그대로 출력해주는 프로그램으로 계속 입력을 받고 엔터를 누를때 까지의 값을 그대로 출력해주는데 이 프로그램을 시작하면 언제던지(내가 원할때) 끝내야만 할 것이다.
이 프로그램을 종료 시키려면 입력받은 값이 EOF이라면 종료를 하게 만들었고 window의 경우는 ctrl + z를 입력한 후에 엔터를 눌러주면 빠져나가면서 프로그램이 종료된다.

엔터를 쳐도 종료가 되지 않고

새롭게 문자열을 입력해도 종료가 되지 않는다 .
이럴때 ctrl + z를 누르면
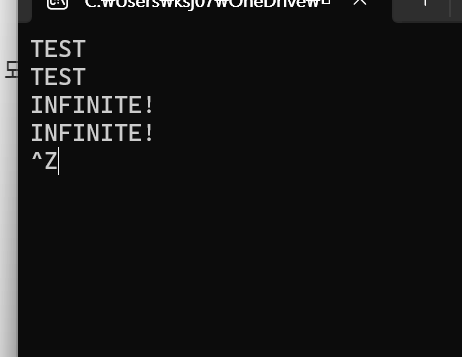
터미널에 이런 문자열이 생성되고 여기서 엔터를 누르면

프로그램이 종료된다.
여기서 주의해야할 점은 ctrl + z 는 단독으로 사용되어야 한다.
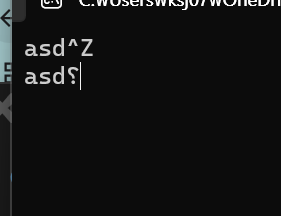
이렇게 중간이나 끝 처음에 널어버리면 프로그램이 종료되지 않는다.
이는 결국 EOF를 EOF로 읽지 못했다는 의미라고 생각된다.
그리고 잘 보면 문자열 자체를 전달하는 것 같지만 이는 사실 한문자씩 쪼개서 읽어들이게 된다.
그래서 문자열 + 엔터키를 합쳐서 한세트로 보고 엔터가 발견되면 그대로 엔터키 까지 반환을 하게 된다.
반환형이 int이고, int형 변수에 문자를 담는 이유?
int getchar(void);
int rgetc(FILE * stream);
이 함수들은 왜 반환형이 char 가 아니라 int 일까?
char형은 예외적으로 signed char가 아니라 unsigned char로 표현하는 컴파일러가 존재한다.
파일의 끝에 도달했을 때 반환하는 EOF는 char가 아닌 -1로 정의되어 있다.
char를 unsigned char로 표현하는 컴파일러는 EOF에 해당하는 -1을 반환하지 못한다.
int는 모든 컴파일러가 signed int로 처리한다. 따라서 -1의 반환에 무리가 없다.
* 결과적으로 char의 경우는 컴파일러에 따라서 signed char와 unsigned char중 랜덤하게 처리한다.
그렇기에 EOF의 값은 -1이고 이걸 처리하기 위해서는 unsigned하면 처리할 수 없고 컴파일러가 무조건 signed로 처리하는 int로 설정하는 경우에는 컴파일러에 따라서 오류가 발생할 여지가 없기 때문에 int를 사용하는 것이다.
줄여서 요약하자면, 이 함수의 반환값의 타입중 문제없이 EOF를 처리할수 있는 타입은 int이기 때문이다.
21-3 문자열 단위 입출력 함수
문자열의 출력 함수 : puts, fputs
#include <stdio.h>
int puts(const char * s);
int fputs(const char * s, FILE * stream);
=>> 성공시에는 0이 아닌값을, 실패시에 EOF반환강사님 께서는 puts를 "풋 스트링"으로 fputs를 "에프 풋 스트링"으로 읽으신다고 한다.
아무튼 puts는 문자열의 주소값을 전달 받는다.
이건 코드로 보자면
puts("ABC");
와 같이 사용될 수 있다는 의미이다.
**앞에서 계속 이야기 했다 싶이 저렇게 그냥 문자열이 오는 경우는 알아서 메모리 공간을 할당해서 값을 넣은 후에 그 주소값을 반환한다고 했었기에 저렇게 넣으면 puts의 인자로 자연스럽게 저 문자열의 주소값(맨 앞 글자의 주소값)을 전달한다.
물론 출력의 대상은 모니터이다.
그리고 바로 다음 fputs은 첫번째 인자로 동일하게 출력하고자 하는 문자열의 주소값을 전달하고, 두번째 인자로는 어디로 출력할 것인지를 지정한다.(앞에 보았던 대로 stdout을 전달하면 모니터로 출력을 지정하는 것이고 FILE로 지정한다면 해당 파일로 출력을 할 수 있도록 지정한다.)
그것 말고도 puts와 fputs의 차이점이 있는데 puts의 경우는 입력된 문자열의 끝에 \n을 추가로 입력해준다.
이는 자동적으로 개행문자을 넣어준다는 의미이다.
fputs의 경우는 입력한 문자만 딱 출력해준다.
예제를 보자면
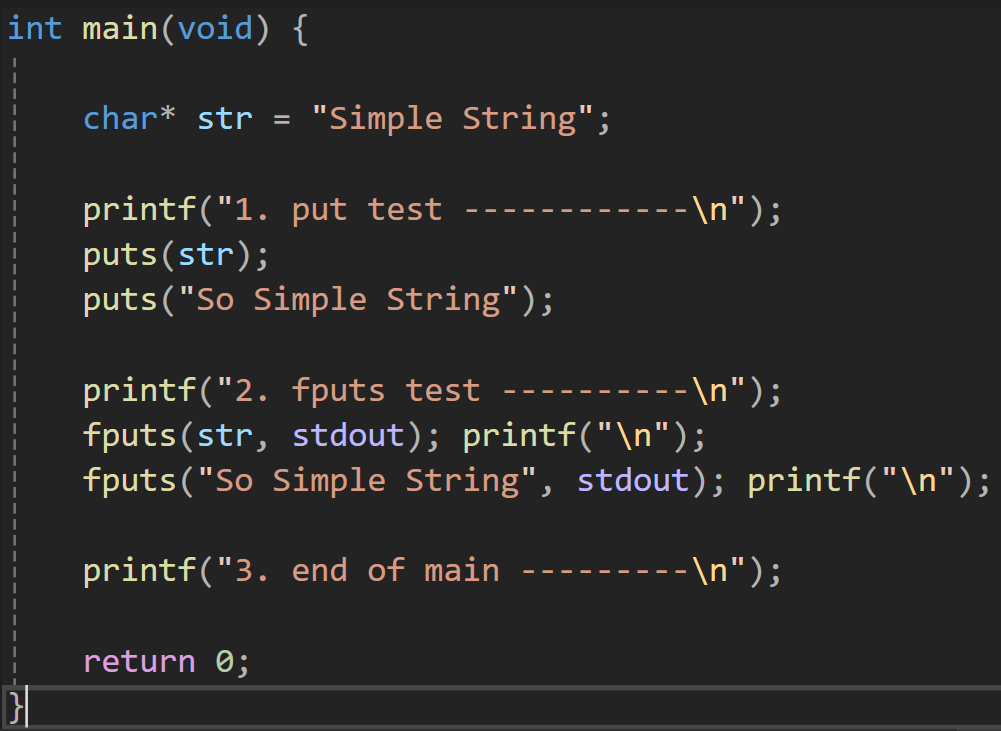

와 같이 출력된다.
말 했던 것처럼 puts에 문자열의 주소값을 넣으면 그 값과 자동적으로 개행을 시켜주나 fputs의 경우는 자동적으로 개행하지는 않는다.
문자열 입력 함수: gets, fgets
#include <stdio.h>
char * gets(char * s);
char * fgets(char * s, int n, FILE * stream);
이번엔 문자열을 입력하기 위한 함수이다.
그런데 이건 기존과는 조금 다르다.
그냥 생각하기에 gets는 키보드로 문자를 입력받을거고, fgets는 어떤걸로 문자를 입력받을지 모르기에 어떤 것으로 입력을 받을지 인자로 추가해줘야만 될것 같다고 생각하겠지만 보면 세개의 매개변수를 받고 있다.
이런 다른 점이 있음을 인지하고 먼저 gets함수를 보자.


gets를 사용하기 위해서는 먼저 저장할 공간을 먼저 마련하고 그 공간에 해당하는 주소값을 gets함수에 전달해야한다.
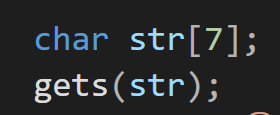
str이 가리키는 메모리 공간에 너가 입력받은 문자열을 저장해라 라는 의미가 된다.
결국 char * s에 해당하는 첫번째 인자는 어떤 곳에다가 입력받은 문자열을 저장할것인지를 지정하는 부분이다.
그리고 fgets의 경우에는 FILE * stream에 해당하는 부분에는 이미 알다싶이 stdin(입력이니까)을 전달하면 키보드를 통해서 문자를 전달하게 된다.
그러면 두번째 매개변수는 어떤것을 의미하는 것일까?
int n 의 경우는 읽어들일 최대 문자열의 길이정보이다.
예를 들어 두번째 인자로 7을 전달하면 이 fgets의 경우는 null문자(\0)를 포함해서 7의 길이만큼 지정하는 것이다.
그러면 이걸 지정하는 이유는 무엇일까?
기존에 gets를 사용할때 썼던 코드를 보자

보면 그냥 공간을 만들고나서 gets로 입력을 받기만하면 그값에 저장되는 것인데, 중요한건 우리가 지정한 배열의 경우는 길이가 7이기 때문에 저장할 수 있는 값이 널문자를 포함해서 7을 넘어 설 수 없는데 gets의 경우는 내가 얼마나 넣을 수 있는지 제한하지 않기 때문에 그냥 쓰는대로 모두 입력을 받는다.
그러면 내가 할당한 7바이트의 메모리 공간을 넘어서서 입력 받은 모든 값을 다 쓰려고 하게 된다.
gets의 경우는 이렇게 사용자가 할당하고자 하는 메모리 공간을 넘어서서 침범하는 경우가 발생할 수 있는 위험성이 있다.
그래서 fgets의 경우는 두번째 인자를 전달해서 저장할 값의 길이를 제한해서 안정적으로 구성할 수 있게 된다.

이렇게 저장할 공간의 길이를 sizeof를 통해서 전달하고 그걸 두번째 인자로 전달해주면

지정한 길이에 해당하는 값 + 널문자의 공간을 제외한 값은 모두 버리게 된다.
그래서 6개의 길이의 문자를 저장하는 것이다.
fgets 함수의 호출의 예
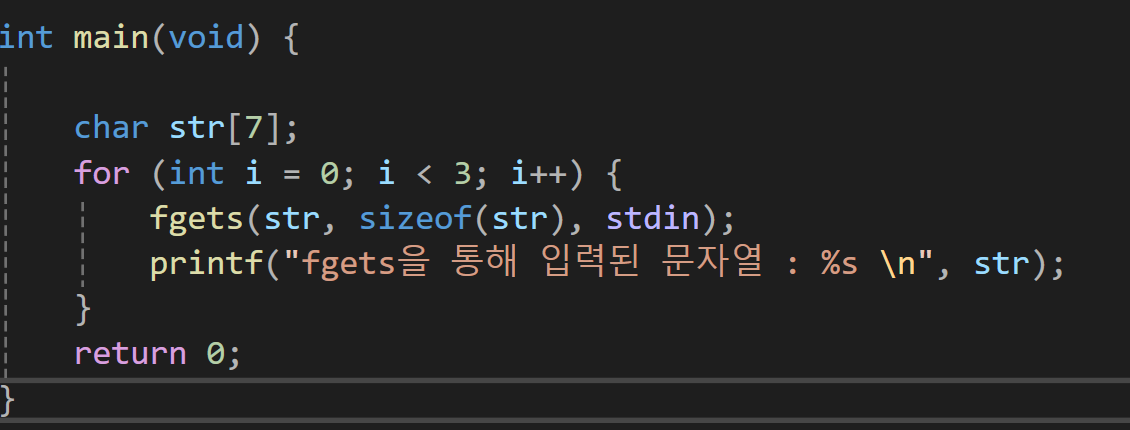
문자를 총 세번 read하고 write하는 것인데, fgets를 호출할때 긴 문자열을 입력한다면

이렇게 값을 루프를 돌면서 반환한다.
여기서 더 길이가 긴 문자열을 전달하면

나중에 끝에 있는 90은 그냥 버려지게 된다.
루프를 돌아서 fgets함수를 호출했는데 입력을 한번만 받고 다시 입력을 받지 않는 이유는 stdin, 입력 스트림에 있는 입력 버퍼 때문이다.
stdin을 fgets함수에 전달하면서 길이가 긴 문자열을 입력했을때 입력 스트림에 존재하는 입력 버퍼는 이 값을 모두 담고 있게 되고, fgets함수가 두번째 인자로 전달한 길이(sizeof(str))에 맞게 값을 잘라서 갖고와서 str에 저장한다(\0널문자를 포함하니 6개씩 읽어오게 된다.)
그러면 처음에 있는 123456\0을 str에 저장하고나서 두번째 루프를 돌때 fgets는 입력 버퍼에 남아 있는 값을 길이만큼 또 읽어들이게 된다. 그러면 789012\0을 읽어서 str에 다시 저장하고 루프를 돌면서 다시 버퍼에 남은 값인 345678을 가져와서 345678\0을 str에 저장한다.
그렇기 때문에 매번 입력을 받지 않는 것이고, 매번 입력을 받는 것을 보고 싶다면 6글자 이하의 값을 입력하게 된다면 루프마다 버퍼가 비어 있기 때문에 값을 다시 주세요 라고 커서가 깜빡이게 될것이다.


이렇게 3번째 루프가 돌때 까지 계속 입력을 요청한다.(저기서 커서가 출력된 값에서 한칸 떨어지는 이유는 엔터 또한 입력한 문자열로 인식해서 출력할때 \n을 같이 출력하기 때문에 한칸씩 계속 띄어져서 나오는 것이다.)
결과적으로 이는 버퍼때문에 생긴 일이라는것..!
아마 아래의 버퍼에서 배울 것 같기에 일단은 대략적으로 버퍼란게 있고 이게 모든 입력 혹은 출력을 받았을때 모든 값을 담아뒀다가 조금 조금씩 갖고가서 쓴다고만 알고 있으면 될것같다..!
그리고 fgets의 경우는 scanf의 경우에서 읽지 못하는 공백 문자도

입력 받을 수 있게 된다.
21-4 표준 입출력과 버퍼
이번에는 위에서 잠깐 말했던 버퍼에 대해서 공부해보자,
지금까지 프로그램에 키보드와 모니터로 입 출력을 했었다
프로그램 상에서 모니터로 데이터를 전송을 하면 바로 모니터로 출력이 이루어진다.
키보드로 데이터를 읽어들일 때도 마찬가지이다.
그렇다보니까 우리가 구현한 프로그램 - 모니터, 키보드가 직접적으로 연결되어 있다는 느낌을 갖게 된다.
그런데 실제로는 우리가 만든 프로그램과 키보드, 모니터 사이에는 메모리공간이 존재한다.
이 메모리 공간은 임시저장소의 역할로써 사용이 된다.
우리가 키보드를 통해 입력한 데이터가 먼저 이 공간에 저장이 된다.
이 공간을 입력 버퍼라고 부른다.
그리고 우리가 printf같은 함수를 통해서 문자 데이터를 모니터로 전송을 하는데 바로 전송을 하는게 아니라 동일하게 메모리 공간에 저장되었다가 출력이된다.
이 공간을 출력 버퍼라고 부른다.
우리가 송수신하는 데이터는 버퍼라는 임시로 데이터를 담아두는 메모리 공간에 저장해둔다.
나중에 배울 파일 입출력의 경우도 동일하게 바로 직접적으로 연결되어 전송되어 입출력이 되는 것이아니라 동일하게 입력 버퍼, 출력 버퍼에 잠깐 저장되어 있다가 파일로 입출력을 하게 된다.
이걸 우리가 체감할 수 있는 부분은 이전에 fgets이나 fgetc의 경우 값을 입력하지 않으면 커서가 깜박거리면서 대기를 하고 있었다.
그 이유는 이 함수들이 실제로 데이터를 읽는 곳은 키보드가 아니라 키보드와 연결된 입력 버퍼이기 때문이다.
시작점을 보자면 키보드를 통해서 입력을 받는 것은 맞으나 실제로 물리적으로 가져오는 위치는 입력 버퍼이다.
그런데 입력 버퍼에 데이터가 존재하지 않는다면 fgets이나 fgetc함수는 입력 버퍼에 데이터가 채워질때 까지 깜빡거리게 된다.
이때 우리가 문자를 입력하고 엔터를 치는 순간에 엔터(\n)를 포함한 문자 데이터들이 입력 버퍼로 이동하게 된다.
그러면서 입력 버퍼에 값이 채워지면 문자가 있음을 인식하고 함수가 이 값을 가져가면서 함수가 종료되게 된다.
종합적으로 이야기 해보자면, 커서가 깜빡이는 이유는 어떤 함수가 입력을 받아서 가져가려는데 버퍼에 값이 비어 있기 때문에 입력을 촉구하기 위해서 대기하는 것이고, 그렇기 때문에 입력은 프로그램과 키보드(입력장치)가 다이렉트하게 붙어 있는게 아니라 입력 버퍼라는 것에서 값을 받아가는 것이고, 입력을 하면 우선적으로 임시로 입력 버퍼에 값이 담기게 된다.
출력 또한 동일하다.
버퍼라는 것은 말 그대로 임시 저장공간이고 임시로 저장을 했다면 그 임시로 저장한 데이터를 언젠가는 비워줘야 한다.
비워 줘야 한다는 의미는 예를 들어 출력버퍼를 비운다는 것은 출력 버퍼에 저장된 데이터를 목적지로 보내버린다는 것을 의미한다.
그러면 임시로 저장한 데이터를 목적지로 보내는 시점은 C언어에서 표준화가 되어 있는 것은 아니다.
이것은 운영체제에 따라서 달라질 수 도 있고 때때로 System레벨에서 직접 컨트롤 할 수 도 있다.
그런데 지금까지 우리가 봤을때 그냥출력하는건 바로바로 출력이 이루어졌는데 버퍼링이 콘솔에 출력하는 경우는 많이 사용하지 않는다.
대표적으로 비워지는 시점은 버퍼가 꽉 찼을때, 주기적으로 일정시간이 되었을때 비우기도 하고, 라인 버퍼라고 해서 라인단위로 문자열이 입력되었을 때마다 버퍼를 비우기도 한다.
우리가 보기에는 사실 버퍼링이 하나도 없는것 같지만 사실은 버퍼링이 이루어 지고 있던것이다.
하나의 예를 들어보자면, fputs를 통해서 'ABC'를 출력하고자 하는데 ABC가 매우 큰 문자열이라고 생각해보면 ABC라는 문자열을 이동시킬때 시간이 오래걸릴 수도 있다.
물론 ABC라고 했지만 이는 예시이고 엄청나게 긴 문자열이고, 이는 하나하나 이동되는게 아니라 블럭으로 나누어서 블럭 불럭 단위로 이동을 실행한다.
이 문자열이 길어서 블럭이 매우 많다면 한번에 이동시킬 수 없게 되는데 우리가 볼때에는 그 문자열이 그냥 동시에 출력된다.
그 이야기는 프로그램에서 아주긴 문자열을 한번에 보내려고 하는데 이게 힘들기 때문에 버퍼에 한문자 한문자 채워서 하나의 문자열을 완성해서 하나의 문자열을 만들어서 한번에 모니터로 출력하는 결과를 여태까지 봤던것이다.
사실 입력버퍼는 이해가 되는데 출력버퍼의 존재를 느끼기가 쉽지 않다.
나중에 File I/O를 공부하게 될텐데 그러면 파일 입출력을 공부하고 나서 10M파일, 100M파일등 파일을 생성할 수 도 복사할 수도 있게 된다.
우리가 프로그램을 1M씩 Write하게 된다면 파일 크기를 파일 탐색기를 통해서 확인할 수 있고 1M씩 쓴다고 해서 1M씩 계속 증가하는게 아니라 100M, 10M등등 어쨋든 우리가 입력한 값보다 크게 한번에 저장한다는 것을 볼 수 있을 것인데, 이게 바로 출력 버퍼 때문에 그렇고 이런 것은 버퍼링이라고 한다.
아무튼 나중에 파일 입출력을 할때 출력 버퍼의 존재를 확인해볼 수 있으면 좋을 듯 하다.
어쨋든 결론적으로는 중간에 메모리 공간, 버퍼가 존재한다는 것인데, 이 버퍼라는 것이 존재하는 이유는 무엇일까.
데이터의 이동은 우리가 생각하는 것보다 내부적으로 많은 리소스의 소모가 있다.
예를 들어 프로그램 상에서 데이터를 입력하고 이 데이터가 파일로 이동하는데 있어서 간단하게 이동하는것 같지만 매우 복잡한 경로를 통해서 물리적으로 파일이라는 장소에 도달하게 된다.
모니터 또한 마찬가지이다.
하나의 문자를 보여주기 위해서 여러가지 규약들을 지켜가면서 매우 복잡하게 이동해서 하나의 문자를 보여주는 것이다.
물론 매우 빠른 속도로 진행되지만 한 문자를 출력하기 위해서 실제 오고가는 데이터의 양은 더 클 수 있다는 것이다.
그래서 프로그램 상에서 데이터를 이동시킨다는 것은 손수레에 데이터를 담아서 이동하는 것과 동일하다고 볼 수 있다
예를 들어 편지 하나를 손수레에 담아서 목적지로 이동했다.
그러고 돌아오니까 편지를 하나 더 전달하라고 한다.
그러면 기존에 보낼때 그냥 보내려고 하는 편지를 뭉치로 손수레에 가득 들고가면 이동하는 빈도가 적어지게 된다.
이렇게 한 문자 한문자를 데이터 송수신 하는것보다 여러개를 묶어서 한번에 송수신하는게 훨씬 더 효율적이라는 것이다.
결과적으로는 성능, 효율을 높이기 위함이라고 생각하면 된다.
우리는 주로 콘솔, 파일을 갖고 입출력을 하는데, 나중에 그외에 기타 물리적인 , 소프트웨어 적인 대상으로 입출력을 하게 되는데 어떻게 하던 입력버퍼와 출력버퍼는 항상 존재한다고 생각하면 된다.
아무튼 전체적으로 내용이 두서없어서 정리가 필요할것이다.
강사님이 정리 한 자료를 다시 보면서 내용을 정리해보도록 하자.
표준 입출력 기반의 버퍼와 버퍼링의 이유
◎입출력 버퍼
- 버퍼는 특정 크기의 임시 메모리 공간(공간이 임시가 아니라 데이터가 잠깐 머물기에 임시)을 의미한다.
- 이 임시로 메모리 공간에 데이터가 저장되는 것을 버퍼링이라고 한다.
- 입출력 버퍼는 운영체제가 만들어서 제공한다.(보통 누가 대신 만들어준거지..? 라고 생각하면 운영체제라고 보면 된다.)
- 표준 입출력 함수를 기반으로 데이터를 입출력 하는 경우는 입출력 버퍼를 거치게 된다.
◎입출력 버퍼에 데이터가 전송되는 시점
- 호출된 출력함수가 반환되는 시점이 출력 버퍼로 데이터가 완전 전송된 시점이다.
함수의 반환시점
** 출력 함수가 반환되는 시점은 언제일까?
보통은 모니터에 데이터가 출력되는 시점이라고 생각하겠지만 사실은 내가 출력하고자 하는 문자열이 출력 버퍼로 모두 전송되는 시점이 출력함수가 반환된는 시점이다. 따라서 실제 함수가 반환되는 시점과 모니터에 출력되는 시점은 일치하지 않을 수 있다.
다시 말하자면 최종 목적지에 데이터가 도달하는 시점이 아니라 출력 버퍼에 모든 데이터가 마지막까지 담기는 시점이 종료 시점이다..!
** 입력 함수가 반환되는 시점은 언제일까?
이건 입력 버퍼로 부터 문자열 하나를 읽어 들였을때 반환된다.
키보드를 통해서 어떤 문자열을 입력하고 엔터를 쳤을때 반환되는게 아니라 이렇게 입력한 문자 데이터가 입력 버퍼에 담겨서 해당 함수로 읽혀졌을때가 반환 시점인 것이다.
정리하자면 입출력 함수의 반환 시점은 최종 목적지가 아니라 버퍼와 관련이 있다고 봐야한다.
- 엔터를 입력하는 시점이 키보드로 입력된 데이터가 입력 버퍼로 전달되는 시점이다.
버퍼링을 하는 이유는 데이터의 이동의 효율성 때문!
출력 버퍼를 비우는 fflush 함수
운영체제에 따라서 내가 어떤 데이터를 입출력하고자 하는 시점에 그 데이터가 입출력이 되지 않을 수 도 있다.
버퍼가 크기 때문에 바로 출력을 하는것이 혹은 바로 입력을 하는것이 비효율적이기 때문에 모아서 입출력을 하려고 기다리는 것이다.
이건 이상한게 아니라 결국 전체적인 프로그램의 운영이 운영체제의 관점에서는 중요하기 때문에 바로 입출력을 실행하는 것보다는 지금 당장 실행 안시키고 나중에 입출력을 실행해도 문제가 없겠다고 인식되면 그 버퍼링 정책에 의해서 딜레이 시키기도 한다.
그런데 우리가 실제로 프로그램을 만드는 우리가 보기에 당장 입출력이 실행되어야 한다고 생각되어 버퍼가 비워지기를 강제하기 위해서 사용하는 함수가 바로 fflush함수이다.
#include <stdio.h>
int fflush(FILE * stream);
=>> 함수 호출 성공시 0, 실패시 EOF반환
이 fflush함수를 실행하면 버퍼가 비워진다.
주의해야 할점은 fflush함수는 출력 버퍼를 비우는 함수이다.
그 이야기는 출력 버퍼와 관련된 stdout과 같은 출력과 관련된 스트림을 전달할 수 는 있는데 입력과 관련된 stdin은 인자로 전달할 수 없다.
그래서 출력 버퍼를 비우라고 함수를 호출하면 버퍼에 있는 값을 지우는게 아니라 목적지로 빨리 전송을 해서 출력을 해라! 라는 의미로 사용된다.
반면에 입력버퍼를 비우는 것은 그 안에 저장된 값을 삭제한다는 의미로 사용이 된다.
일단 출력 버퍼를 비우는건 목적지로 데이터를 전송한다는 사실을 좀더 집중하다.
사용하는 방법은 그냥
fflush(stdout);과 같이 사용하면 버퍼가 비워진다.
그러면 입력 버퍼는 어떻게 비워야할까?
우리가 사용하는 어떤 라이브러리(visual studio를 이야기하는듯 보인다.)의 경우는 fflush(stdin);와 같이 fflush에 입력버퍼의 정보의 전달을 허용하는 경우도 있다.
근데 이건 표준이 아니다.
다른 컴파일러를 사용하면 이런 사용을 허용하지 않는다.
아무튼 이렇게 사용하면 안된다.
그러면 입력 버퍼를 어떻게 비우면 될까?
사실은 출력 버퍼를 비우는 것은 fflush라는 함수를 호출하지면 비울수가 없다.
그런데 입력 버퍼의 경우는 그냥 단순히 Read하면 버퍼에 남지를 않는다.
즉 입력 버퍼를 비우는 함수는 별도로 제공할 필요 없이 알고 있는 함수들을 통해서 문자열을 그냥 읽어버리면 되기 때문이다.
그걸 활용할 필요 없이 그냥 비우길 원한다면 그냥 날리면 된다.
- 출력 버퍼를 비운다는 것은 데이터를 지우는게 아니라 목적지로 데이터를 보낸다는 것을 의미한다.
- 출력 버퍼를 비우기 위해서는 fflush함수를 사용해야하고 fflush의 경우는 stdin을 받아준다고 그걸 사용해서는 안된다, 오직 출력버퍼를 위해서만 사용해야한다.
- 입력 버퍼를 비우는 것은 데이터를 지우는 것을 의미하고 이를 수행해주는 함수는 따로 있는게 아니라 read해주는 어떤 함수를 사용하던 읽어버리면 입력 버퍼가 비워지게 된다.
입력 버퍼는 어떻게 비워야 할까


주민번호 앞자리를 작성하고 엔터를 치는 순간 엔터가 버퍼에 남아서 이름을 입력할때 엔터가 들어가고 이름에는 공백문자인 \n이 저장되어 버리는 문제점이 발생했다.
또한 주민번호 앞자리만 쓰라했는데 전문을 다 작성하는 경우

이렇게 버퍼에 남은 숫자들로 인해서 이름을 입력받을 수 없게 된다.
그래서 입력 버퍼를 비우는 함수를 이름의 입력을 받기 이전에 비워서 정상화시켜보도록 하자.

이렇게 함수를 하나 상단에 정의하고 (getchar를 통해서 버퍼에 있는 값을 \n(공백문자)까지 읽어서 반환하는데 이걸 어디에 저장하지 않고 날려버리니 이건 결론적으로 그냥 버퍼를 비우는 역할만 하는것이다.)

이렇게 이름입력 전에 비워버리면

이렇게 입력버퍼에 담겨있던 엔터가 비워지면서 이름의 입력을 새로받게 된다.
또한 내가 원하는 길이보다 큰 입력을 받아 이름을 받지 못했던 예제도

원하는 데이터를 받을 수 있게 되었다.
21-5 입출력 이외의 문자열 관련 함수
문자열과 관련된 여러가지 함수중 기억해야할 함수들을 공부해보자
문자열의 길이를 반환하는 함수: strlen
#include <stdio.h>
size_t strlen(const char * s);
=>> 전달된 문자열의 길이를 반환하되, 널 문자는 길이에 포함하지 않는다.
size_t라는 자료형은 typedef라는 선언에 의해서 만들어진 자료형이다.
typedef는 나중에 배울 것인데 간단히 이야길 해보자면
typedef unsigned int size_t;라고 선언하면 size_t를 unsigned int로 간주하겠다는 의미가 된다.
이게 typedef의 의미이다.
이제 위 코드를 선언한 이후부터는 size_t를 unsigned int로 인식하게 된다.
아무튼 여기서 이야기한 size_t는 unsigned int라고 생각하면 된다.
함수로 돌아와서 strlen함수의 인자로 문자열의 주소값을 전달하면 결과로 문자의 길이를 반환하는데 널문자의 길이는 포함하지 않고 반환한다.
사용방법은 매우 간단하다.
char str[] = "1234567";
printf("%u \n", strlen(str));이렇게 strlen에 문자열의 주소를 전달하면 이 문자열의 길이를 반환한다.
사실 이 구조도 간단한게 그냥 널문자를 만날때까지 세서 반환하는 것이다.
아무튼 문자열의 길이인 7이 전달되면서 7이 출력된다.
그리고 반환값이 unsigned int이기 때문에 %u로 출력 했는데 일반적으로 양의 정수이더라도 %d로 출력이 가능하기에 %d로 많이 출력을 한다.
보통 unsigned int가 표현할 수 있는 길이가 훨씬 크긴 하지만 문자열의 길이가 몇천, 몇백, 몇만은 아니기 때문에 궂이 %u로 출력할 필요는 없다.
보통 그냥 양의 정수가 반환이 되나 보통 문자열의 길이는 %d, int의 크기를 벗어나는 경우가 없기 때문에 %u나 %d나 동일하게 출력해도 무방하다라고 생각하면 된다.
이 함수는 사용하는 방법이 매우 간단하기 때문에 함수를 활용하는 방법에 대해서 하나 예시를 보여주겠다.
문자열을 입력할때 마지막에 엔터를 치면서 종료하기 때문에 항상 개행 문자가 삽입되는데 이 개행문자를 삭제하는 것은 strlen을 사용해서 처리할 수 있다.
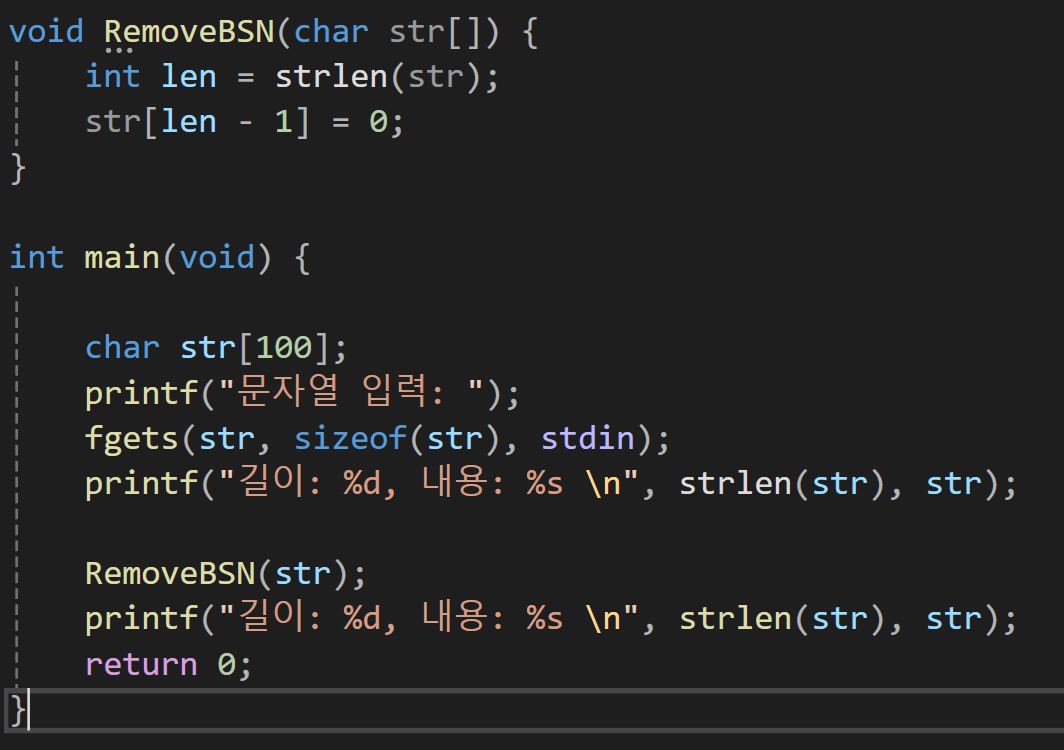
먼저 fgets를 통해서 값을 전달 받으면 엔터를 기준으로 입력을 종료하게 된다.
이때 fgets의 경우는 엔터, 개행문자를 포함하게 되고 그 값과 길이가 str에 저장되게 된다.
이 개행문자를 제거하기 위해서 RemoveBSN에 배열의 주소값을 전달하고 그 함수 내부에서 strlen에 str을 전달하고 그 길이는 널문자를 제외한 길이를 반환한다.
예를 들어 입력한 문자가 1234567+엔터 라면 1234567\n\0이 저장될 것이고 strlen은 전체길이를 확인하면 8을 반환하게 될것이다.
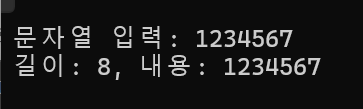
이때 str[7]은 \n(개행문자)를 의미하고 이걸 0을 넣어서 널문자로 변경해버리면

공백문자가 있던 자리가 널문자가 되면서 문자열의 종료로 인식하게 된다.
그러고 strlen과 fgets에 str을 넣어주면 길이가 \n을 제외한 값으로 인식하게 된다.

문자열을 복사하는 함수들: strcpy, strncpy
#include <string.h>
char * strcpy(char * dest, const char * src);
char * strncpy(char * dest, const char * src, size_t n);
=>> 복사된 문자열의 주소 값 반환
strcpy의 경우는 src로 들어온 문자열을 dest에 복사하는 기능을 한다.
그런데 src에 들어오는 값과 dest에 들어오는 값은 모두 주소값을 인자로 전달한다.
src에는 원본이 되는 문자열의 주소값이, dest에는 복사가 될 메모리공간의 주소값이 전달되어야 한다.
strncpy의 경우는 src에 전달된 문자열을 dest에 복사를 하는데, 복사하는 최대 문자열의 길이를 n으로 제한한다.
여기서 최대한이라는 말은 제한한 문자열의 길이에 꽉 맞는 데이터를 dest에 넣는게 아니라 적게 들어가면 적게 들어간 만큼의 크기를 복사하는 거고 제한한 크기보다 작더라도 제한 크기로 데이터를 dest에 집어넣는다는게 아니라는 것임.
그래서 3번째 인자는 두번째 인자로 전달된 문자열의 길이가 3번째 인자로 전달된 정수보다 큰경우만 의미가 있을 것이다.
그러나 일반적으로는 strcpy를 많이 쓰는데 안정적으로 코드를 구성하고자 한다면 strncpy를 사용하는 게 좋다.
그니까 strcpy의 경우는 dest의 길이와는 무관하게 src의 크기가 크면 dest에 큰만큼 다 넣으려고 하기 때문에 문제가 생길 가능성이 존재한다.
그런게 strncpy를 사용하면 마지막에 전달되는 size_f를 dest의 길이에 맞추면 src의 크기가 크더라도 크기를 dest의 크기로 제한하기 때문에 문제가 발생할 여지가 매우 적어지기 때문이다.
그래서 strncpy의 경우는 보통
char str1[30] = "Simple String";
char str2[30];
strncpy(str2, str1, sizeof(str2));와 같이 사용법이 고정되어 있다.
세번째 인자는 첫번째 인자의 sizeof로 넣어주는 것이 통상적으로 사용된다고 한다.
그런데 보통은 메모리 공간을 매우 넉넉하게 설정하고 복사를 하기 때문에 strcpy를 많이 사용한다.
원리원칙만 따지면 strcpy대신 strncpy를 더 사용하는게 맞지만 이건 그냥 상황에 따라서 사용하도록하자.
strncpy 함수를 잘못 사용한 예
strncpy를 사용해서 문자열을 복사할때 생각해야할 부분은
char str1[] = "12345";로 구성되어있을때 이를 복사할 str2의 크기가 3일 경우에
str1을 str2에 복사하려고 할때 생기는 두가지 케이스가 있다.
첫번째는 str2에 123을 넣어서 널문자를 넣지 않겠다고 하는 케이스가 있고 두번째는 12를 넣고 마지막에 널문자를 넣어 복사하는 케이스가 있을 것이다.
이건 정답이 있는 것은 아니고, 프로그램을 만들다보면 전자가 필요한 경우가 있고 후자가 필요한 경우도 있다.

case2를 보면 꼭 널문자를 복사해야한다는 조항이 없이 만들어져있다.
이 경우를 원하는 경우도 분명 있다.
그런데 이걸 문자열로 인식해서 출력을 하려고 했던 시도 자체가 잘못이다.(puts함수를 사용한 경우, 널문자를 만날때까지 출력하기 때문에 배열을 모두 본 이후로도 널문자를 만날때까지 무한히 이 방식은 문제가 있는건 맞다)

이렇게 끝난건 어쩌다 보니 배열부터 쪽 읽다가 널문자를 만났기 때문에 종료된것이다.
사실 널문자를 못만났다면 언젠가 또 널문자를 만날때 까지 출력했을 것이다.
널문자를 보장하는 작성법은 널문자가 들어갈 공간을 남기고 복사를 진행하고 마지막에 널문자를 넣어주면 된다.

이렇게 sizeof의 크기에 -1을 해서 한칸을 남기고

마지막 칸에는 널문자에 해당하는 아스키 코드값인 0을 넣어주면 된다.
그러면 1234까지 복사한 다음에 마지막에 널문자를 넣어서 정상적으로 출력이 가능하다.

이건 옳다 틀리다의 개념보다는 상황에 따라서 사용해야하는 것이기 때문에 두 방법을 모두 인지하고 있어야한다.
문자열을 덧붙이는 함수들: strcat, strncat
#include <string.h>
char * strcat(char * dest, const char * src);
char * strncat(char * dest, const char * src, size_t n);
=>> 덧붙여진 문자열의 주소값 반환덧붙이다, 연결하다의 뜻을 가진 concatenation의 cat을 사용한 함수 이름이다.
이건 배열을 src에 문자열을 dest의 뒤에 붙여서 연장하는 기능을 한다.
물론 dest 배열 자체의 크기가 늘어나는건 아니고 dest의 문자열에 src에 있는 문자열을 합친다고 생각하면 된다.
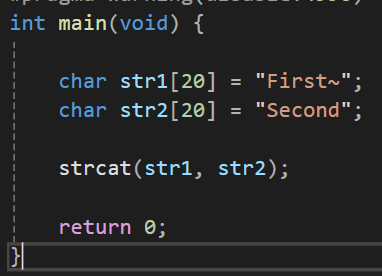

src에 있는 문자열의 마지막에 존재하는 널문자의 위치부터(널문자를 제거하면서) str2를 붙여주는 것이다.
그래야 문자열의 종료를 덧붙여진 글자의 끝으로 인식하게 된다.
그렇기에 strcat을 사용한다면 dest의 크기가 src를 붙였을때 이걸 모두 수용할 수 있는 크기를 가져야만 한다.
그리고 strncat함수의 경우는 마지막에 넣는 인자가 덧붙여지는 문자의 최대 길이를 제한하는데 n을 넣는다면 널문자의 공간을 포함해서 n +1의 크기로 길이를 제한한다.

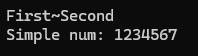
여기서 보면 Simple num : 하고 1234567이 출력이 되는데 크기를 7로 제한했는데도 7글자가 모두 출력 되었고 종료가 정상적으로 된것을 보면 자동적으로 종료 부분에 널문자를 넣어주고 사이즈는 7 + 1로 제한하는 것을 알 수 있다.
문자열을 비교하는 함수들: strcmp, strncmp
#include <string.h>
int strcmp(const char * s1, const char * s2);
int strncmp(const char * s1, const char * s2, size_t n);
=>> 두 문자열의 내용이 같으면 0, 같지 않으면 0이 아닌 값 반환
strcmp는 두개의 문자열의 전체를 비교하고 strncmp는 두개의 문자열의 부분을 비교하는 함수이다.
그래서 strncmp는 앞에서 얼마만큼의 양을 서로 비교할지를 마지막 전달인자로 전달 받는다.
위에 보이는 예시를 봤을때
- s1(첫번째 매개변수로 전달된 문자열)이 더 크다면(크다는 의미는 아래에 추가적으로 설명할 예정) 0보다 큰 값을 반환한다.
- s2(두번째 매개변수로 전달된 문자열)이 더 크다면 0보다 작은 값을 반환한다.
- s1과 s2의 내용이 모두 같다면 0을 반환한다.
여기서 특정 숫자가 아니라 0보다 큰값, 0보다 작은값으로 설명한 이유는 어떤 특정 기준은 없이 양수/음수로만 표현되기 표준으로 작성되어 있기 때문이다.(값은 컴파일러에 따라 달라질 수 있음)
위에서 크다 작다에 대한 기준은 아스키 코드 값을 근거로 한다.
//두 문자열을 비교했을때 아스키 코드 값을 기준으로서 크고 작음에 대한 이해
"AAB" === "AAC"
//첫번째 글자
A = A
//두번째 글자
A = A
//세번째 글자
B < C
//A보다 B가 크고 B보다는 C가 더 큼, 대문자보다 소문자가 아스키 코드의 값이 더 큼
//또한 순서대로 비교 했을때 어떤것이 먼저 크다 작다가 판별이 나버리면 그 순간 해당 문자열이
더 큰 문자열로 결론이남
"aCC" === "ZDD"
//첫번째 글자
a > Z
//크다 작다에 대한 내용이 나오면 여기서 종료..!
사전편찬순서를 기준으로 뒤에 위치할 수 록 더 큰 문자열로 인식해도 된다.
printf("%d", strcmp("ABCD", "ABCC")) // => 0보다 큰 값이 출력
printf("%d", strcmp("ABCD", "ABCDE")) // => 0보다 작은 값이 출력"ABCD"와 "ABCDE"의 비교는 ABCD 다음에 문자열의 종료를 의미하는 널문자 아스키 코드값으로 0인 값이 들어 있고 E는 0보다 크니까 후자가 더 크다고 나오기에 0보다 작은 값이 출력된다.
그런데 어차피 사용법은 다르냐 안다르냐에 대한 내용을 볼거기 때문에 그냥 같으면 0 다르면 0이 아닌 값을 반환한다고 인식하고 있어도 충분하다.
조금 깊게는 아스키코드값으로 비교하고 널문자까지도 비교한다 정도..?
그 이상은 별로 확인할 일은 없을 것이다.
문자열 비교의 예

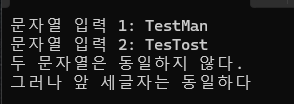
여기까지 문자열 관련 함수들은 사용빈도수가 높은 함수이다.
그러니 기억하고 있다가 참조 하면 좋을 것 같다.
그 이외의 변환함수들
프로그램을 만들다 보면 타입을 변환해야 하는 경우가 자주 생긴다.
예를들어서
char str[] = "123" ===> int 형 123으로 변환
char str[] = "3.14" ===> double형 3.14로 변환과 같은 작업을 할때 변환이 불가능한것은 아니나 매우 번거로운 작업일 수 없다.
이를 간단하게 사용할 수 있게 함수를 제공하고 있다는 사실은 우리의 시간을 아껴주는 C의 아주 작은 배려라고 생각한다.
그럼 변환을 시켜주는 함수들을 한번 확인해보자.
int atoi(const char * str); ---- 문자열의 내용을 int형으로 변환
long atol(const char * str); ---- 문자열의 내용을 long형으로 변환
double atof(const char * str); ---- 문자열의 내용을 double형으로 변환
//이때 헤더파일 stdlib.h을 include 해줘야 한다.
이걸 사용하는 방법은

와 같다.

'Programming Language > C' 카테고리의 다른 글
| 열혈 C - Chapter 23 구조체와 사용자 정의 자료형2 (1) | 2024.10.31 |
|---|---|
| 열혈 C - Chapter 22 구조체와 사용자 정의 자료형1 (1) | 2024.10.28 |
| 열혈 C - Chapter 19 함수 포인터와 void 포인터 (2) | 2024.10.19 |
| 열혈C - Chapter 18 다차원 배열과 포인터의 관계 (0) | 2024.10.18 |
| 열혈C - Chapter 17 포인터의 포인터 (1) | 2024.10.13 |